In SEO, you’ll often hear about canonicalization. But what is it?
Imagine your website has multiple URLs leading to the same content. This can confuse search engines. That’s where canonical tags come in.
Canonical tag tells search engines which page is the preferred one. By using them right, you tidy up your site, make it easier to index, and improve your SEO.
Stick with us to learn more about canonicalization and how it can boost your website’s visibility and traffic.
What is Canonicalization?
Canonicalization is the method used to choose the preferred URL or webpage when there are multiple URLs that have similar or identical content.
The purpose of this is to prevent problems with duplicate content, combine signals that determine page ranking, and make sure that search engines recognize the most important and trustworthy version of your content.
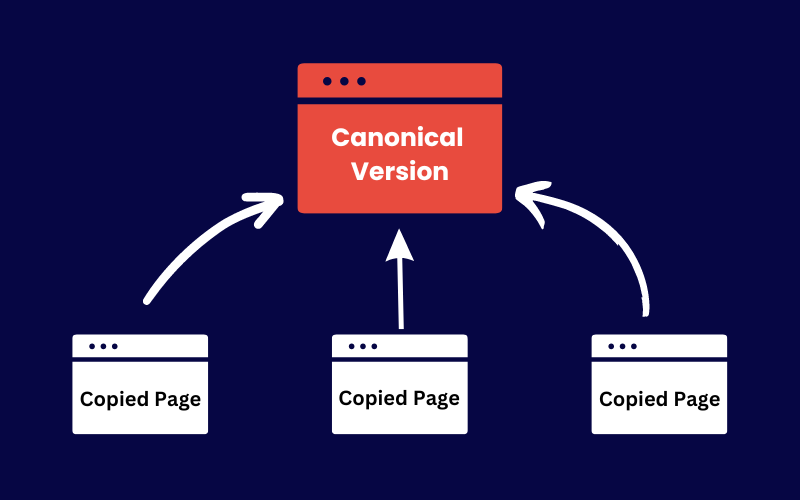
What is Canonical URL
Canonical URL is the preferred version of your page that you want search engines to prioritize.
Imagine you have a website page called www.example.com/article. As time goes on, different versions of this page have appeared, like :
www.example.com/article/,
www.example.com/article?utm_source=email,
www.Example.com/Article,
www.example.com/article/amp,
and example.com/article.
While these variations all show the same content, search engines see them as duplicate content. To prevent confusion and make sure your page ranks well in search results, you need to establish a canonical URL.
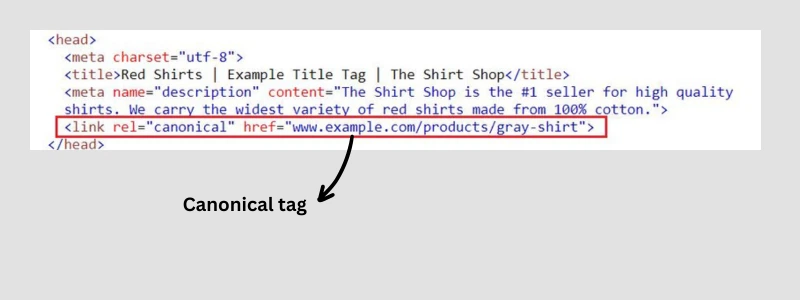
What is Canonical Tag
A canonical tag is a piece of HTML code that you include on your webpage to let search engines know which URL you prefer.
rel=“canonical “
How Does Canonicalization Work?
Here’s how canonicalization usually works:
1. Identification: Search engines find different URLs that all lead to the same or similar content on a website.
2. Selection: The preferred version of the content, called the canonical URL, is chosen. This decision can be made by the website owner or by computer algorithms.
3. Implementation: The chosen canonical URL is specified using a special tag (rel=”canonical”) in the HTML header of the webpage. This tag tells search engines that the content should be credited to the specified canonical URL.
4. Indexing: Search engines recognize the canonical tag and gather the ranking signals for the specified URL. This improves the efficiency of indexing and prevents problems caused by having duplicate content.
Canonicalization Signals
The process of canonicalization depends on different signals that help search engines, like Google, figure out the most preferred version of a webpage. About 20 different signals are involved in making this decision. These signals are based on various factors:
1. Duplicate Identification:
Search engines detect duplicate content across the web to identify which version should be prioritized for indexing.
2. Canonical Link Elements:
Websites use canonical tags in HTML to specify the preferred URL for search engines to index.
3. Sitemap URLs:
XML sitemaps provide information to search engines, including canonical URLs for webpages.
4. Internal Links:
The structure of internal linking within a website influences which pages are considered more important.
5. External Links:
Incoming external links signal to search engines the popularity and authority of a webpage.
6. Redirects:
Permanent redirects (301 redirects) are used to guide traffic from one URL to another, indicating the preferred URL.
7. Hreflang:
Signals related to language and regional targeting for international websites assist in determining the most relevant version of a webpage for specific audiences.
8. PageRank:
Google’s ranking algorithm assesses the authority and relevance of webpages, affecting their ranking in search results.
9. HTTPS > HTTP :
Secure HTTPS pages are favored over non-secure HTTP pages, influencing the canonicalization process.
10. Shorter URLs > Longer URLs:
Search engines may prioritize concise URL structures over lengthy ones.
11. Original Content Source:
The initial publication or source of content influences which version is considered the original.
12. Site-Level Signals:
Factors such as a website’s history of scraped content contribute to determining the preferred version of webpages.
13. Pages > PDFs:
Webpages are typically preferred over PDF documents in search results, affecting canonicalization decisions.
All of these signals together help Google decide which version of a page should be considered the main one.
Do I Have Duplicate Content on My Website?
Wondering if your website has duplicate content? It’s more common than you might think! Duplicate content can quietly find its way onto your site without you noticing.
Let’s explore some typical situations:
Different Regions:
First, let’s talk about how content can be different for various regions. When content is specifically created for different regions or languages, it can accidentally create duplicate pages with regional differences.
Different Devices:
Similarly, we should consider how content can vary depending on the device you’re using. Pages that are optimized for different devices, like desktop computers or mobile phones, might create multiple versions of the same content.
Different Protocols:
Next, let’s think about how different protocols can cause duplication. If a page can be accessed through both HTTP and HTTPS protocols, it can accidentally create duplicate content.
Site Functions:
Moving on to site functions, we need to address how they can also contribute to duplication. Dynamic content generated by site functions, such as search results or filters, can unintentionally create duplicate pages.
Accidental Duplicates:
Moreover, it’s not uncommon to have accidental duplicates. Technical errors or misconfigurations can lead to unintentional duplication of content.
Non-WWW and WWW Versions:
Think about the existence of non-WWW and WWW versions of a website. Having both versions can unintentionally create duplicate pages.
URLs and Trailing Slashes:
Another factor to consider is the impact of URLs and trailing slashes. Different URLs that point to the same content, with or without trailing slashes, can contribute to duplication.
URLs With and Without Capital Letters:
Similarly, URLs that have inconsistent capitalization can be problematic. Inconsistent capitalization in URLs may accidentally create duplicate pages.
Default vs. Alternative Versions:
Let’s also think about the difference between default and alternative versions of content. If there are multiple versions of the same content, like print-friendly or mobile-friendly versions, it can unintentionally lead to duplication.
URL Parameters:
Dynamic URLs that have parameters like sorting options or session IDs can generate duplicate content.
Scraped or Syndicated Content:
Lastly, we should consider the presence of scraped or syndicated content. When content is copied from other sources without proper attribution or canonicalization, it can significantly contribute to duplication.
How to Implement Canonicalization
There are a couple of ways you can put canonical tags on your website.
The first method is a bit tricky and involves adding code directly into the HTML of your pages. This code goes into the section of your page and looks something like this:
< link rel=”canonical” href=”preferred-url” />
If you’re not sure how to do this, you can ask your web development team or agency to handle it for you.
The second method is much simpler.
You can add your canonical tags directly into your content management system (CMS) or use a plugin designed for this purpose.
Here’s how you can do it on some popular platforms:
WordPress:
Instead of messing with HTML, you can use plugins like Yoast, All in One, or Rank Math to set up canonical URLs easily.
Magento:
You can set canonical links within your store’s settings, but, this feature only works for product pages. For other parts of your website, you might need extensions that help with this.
Shopify:
You can edit your website’s theme file to add a canonical tag, or use apps like the Canonical Tag URL Wizard if you’re not comfortable with coding.
Squarespace:
There’s a feature called code injection that lets you add a canonical tag to specific pages without much hassle.
Wix:
You can tweak the canonical tag through the SEO basics menu without diving into complex coding stuff.
Canonical Tags vs. 301 Redirects
A common question in SEO is whether canonical tags work like 301 redirects to transfer link authority. While they generally have a similar effect, it’s important to understand that they produce different outcomes for search engines and visitors.
In the case of a 301 redirect from Page A to Page B, users are immediately taken to Page B and don’t see Page A at all.
However, when using a rel-canonical tag from Page A to Page B, search engines consider Page B as the main one while still allowing users to access both URLs. The right approach depends on your specific goals.
Common Mistakes With Canonicalization
Here are a few common mistakes in canonicalization :
#1. Blocking the canonicalized URL via robots.txt :
When a URL is blocked in robots.txt, Google is unable to crawl the website and as a result, cannot detect any canonical tags on it. It therefore cannot transmit any “link equity” from the non-canonical to the canonical.
#2. Setting the canonicalized URL to “noindex” :
It is important to not mix the use of “noindex” and “rel=canonical” tags because they give conflicting instructions.
According to John Mueller, when it comes to Google, the canonical tag is typically given more priority over the “noindex” tag.
#3. Setting a 4XX HTTP status code for the canonicalized URL :
When a canonicalized URL is set to a 4XX HTTP status code, something similar occurs as when a “noindex” tag is utilized. In these cases, Google is unable to identify the canonical tag as a result it will not attribute “link equity” to the canonical version.
#4. Canonicalizing all paginated pages to the root page :
It is not recommended to canonicalize all paginated pages (like page 2, page 3) into the root page (page 1). Instead, use rel=”prev” and rel=”next” tags to indicate the connection between paginated pages and specify the canonical URL for each page.
#5. Using the URL removal tool in Google Search Console for canonicalization :
If you use the URL removal tool in Google Search Console to remove canonicalized URLs, it can result in your content being removed from search results. This tool is meant for temporary removals and should not be used to manage canonicalization.
#6. Not keeping canonicalization signals consistent :
Inconsistencies in canonical tags across pages can confuse search engines and lead to improper indexing and ranking of content.
#7. Not using canonical tags with hreflang :
Hreflang tags are used to show which language and region a website is targeting internationally. If canonical tags are not used correctly with hreflang tags, it can cause problems with how search engines index and rank content in multiple languages.
#8. Having multiple rel=canonical tags :
If a page has more than one canonical tag, it can confuse search engines and cancel out the desired signal for canonicalization.
#9. Rel=canonical in the <body> :
Canonical tags should be placed in the <head> section of a webpage, and placing them in the <body> section can lead to improper interpretation by search engines.
Related Articles You May Find Useful:
SEO for Startups: The Ultimate Guide to Organic Growth







